

Project
Flora Lighthouse
Hoe kom je er als student achter wat de meest efficiente manier is om te studeren? Artificial Intelligence (AI) staat


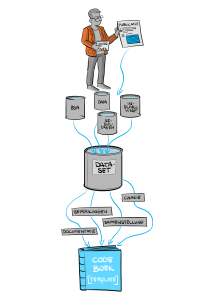 Op dinsdag 23 maart vond het webinar over de simulatiedataset voor universiteiten plaats van de zone Veilig en betrouwbaar studiedata benutten. Deze dataset is sinds half februari beschikbaar; hoog tijd dus om hier wat meer aandacht aan te besteden. Centraal tijdens het webinar stonden de vragen wat de aanleiding was om deze dataset te bouwen, hoe de dataset tot stand kwam en welke kansen deze biedt.
Op dinsdag 23 maart vond het webinar over de simulatiedataset voor universiteiten plaats van de zone Veilig en betrouwbaar studiedata benutten. Deze dataset is sinds half februari beschikbaar; hoog tijd dus om hier wat meer aandacht aan te besteden. Centraal tijdens het webinar stonden de vragen wat de aanleiding was om deze dataset te bouwen, hoe de dataset tot stand kwam en welke kansen deze biedt.
Na opening door Bram Enning, aanvoerder van de zone Studiedata, lichtte Theo Bakker toe hoe het idee voor deze dataset is ontstaan. Het begon een jaar geleden, toen Theo Bakker vanuit de Vrije Universiteit aanvoerder was van de zone Studiedata. Destijds kwamen er binnen de VU verzoeken van studenten om onderzoek te doen op de dataset van de VU. Dit was niet mogelijk, omdat ze daarmee studiedata ter beschikking zouden krijgen die mogelijk herleidbaar zou zijn naar andere studenten. Een gemiste kans voor de enthousiaste studenten.
Ook met collega’s uit verschillende instellingen is het enkel mogelijk beschrijvingen te geven van welke analyses je maakt. Datasets met elkaar delen kan vanwege de privacygevoelige gegevens niet. Daarom kwam het idee om een ‘Titanic dataset’ te bouwen, wat er nog niet was in Nederland. Met de komst van het Versnellingsplan was het mogelijk om dit project tot uitvoering te brengen, zo vertelde Theo.
De zone werkte met een projectleider uit de EUR, Dominique van Deursen, en twee programmeurs van de VU, Katja van der Perk en Jurriaan Janssen. Daarnaast zijn de privacy officers van de VU nauw betrokken. Deze nieuwe synthetische dataset biedt hopelijk vele nieuwe mogelijkheden.
Na de presentatie van Theo vertelde projectleider Dominique van Deursen waarom het nodig was een gesimuleerde dataset te bouwen, die dus niet geanonimiseerd of gepseudonimiseerd is. Je hebt een dataset nodig die de juiste kenmerken heeft om in een vroeg stadium dingen te kunnen testen, zonder persoonsgegevens te gebruiken. Voor dit project stelde ze van tevoren drie eisen op, zo vertelde Dominique:
Wat de simulatiedataset precies bevat? Een csv bestand, een markdown file (inclusief de statistische verantwoording) en een R script. En hoe je de dataset op eigen computer kan openen? Ga naar de repository in Bitbucket en klik op de knop ‘clone’ rechts bovenin.
In het bouwen van de simulatiedataset zijn acht stappen doorlopen:
Als je zelf een simulatiedataset wilt simuleren vind je in map 6 een csv bestand dat je hiervoor kunt gebruiken.
Hoe kom je er als student achter wat de meest efficiente manier is om te studeren? Artificial Intelligence (AI) staat

Over studiedata en het belang ervan voor het monitoren en verbeteren van studiegedrag is al veel geschreven. Met de opkomst

Studiedata bieden steeds meer mogelijkheden om het hoger onderwijs beter, effectiever en efficiënter te maken. Om de voordelen te kunnen

Waar en hoe kunnen hoger onderwijsinstellingen regie op studiedata krijgen bij het gebruik van tooling van leveranciers? De zone Veilig